Overview
GLM-4.6V series are Z.ai’s iterations in a multimodal large language model. GLM-4.6V scales its context window to 128k tokens in training, and achieves SoTA performance in visual understanding among models of similar parameter scales. Crucially, GLM-4.6V integrate native Function Calling capabilities for the first time. This effectively bridges the gap between “visual perception” and “executable action,” providing a unified technical foundation for multimodal agents in real-world business scenarios.- GLM-4.6V
- GLM-4.6V-FlashX
- GLM-4.6V-Flash
Positioning
Flagship, Highest Performance
Input Modality
Video / Image / Text / File
Output Modality
Text
Context Length
128K
Positioning
Lightweight, High-Speed,and Affordable
Input Modality
Video / Image / Text / File
Output Modality
Text
Context Length
128K
Positioning
Lightweight, Completely Free
Input Modality
Video / Image / Text / File
Output Modality
Text
Context Length
128K
Resources
- API Documentation: Learn how to call the API.
Introducing GLM-4.6V
Native Multimodal Tool Use
Traditional tool usage in LLMs often relies on pure text, requiring multiple intermediate conversions when dealing with images, videos, or complex documents—a process that introduces information loss and engineering complexity.GLM-4.6V is equipped with native multimodal tool calling capability:
- Multimodal Input: Images, screenshots, and document pages can be passed directly as tool parameters without being converted to text descriptions first, minimizing signal loss.
- Multimodal Output: The model can visually comprehend results returned by tools—such as searching results, statistical charts, rendered web screenshots, or retrieved product images—and incorporate them into subsequent reasoning chains.
Capabilities & Scenarios
- Intelligent Image-Text Content Creation & Layout
- Visual Web Search & Rich Media Report Generation
- Frontend Replication & Visual Interaction
- Long-Context Understanding
GLM-4.6V can accept multimodal inputs—mixed text/image papers, reports, or slides—and automatically generate high-quality, structured image-text interleaved content.
- Complex Document Understanding: Accurately understands structured information from documents containing text, charts, figures, and formulas.
- Visual Tool Retrieval: During generation, the model can autonomously call search tools to find candidate images or crop key visuals from the source multimodal context.
- Visual Audit & Layout: The model performs a “visual audit” on candidate images to assess relevance and quality, filtering out noise to produce structured articles ready for social media or knowledge bases.
GLM-4.6V delivers an end-to-end multimodal search-and-analysis workflow, enabling the model to move seamlessly from visual perception to online retrieval and finally to structured and illustrated report generation. Across the entire process, it maintains multimodal context awareness and performs reasoning grounded in both textual and visual information.
- Intent Recognition and Search Planning: For queries containing images, text, or both, GLM-4.6V identifies the user’s search intent and determines what information is needed. It then autonomously selects and triggers the appropriate search tools (e.g., text-to-image search, image-to-text search, or image-to-image matching) to retrieve relevant data.
- Multimodal Results Alignment: The model reviews the mixed visual and textual information returned by the search tools, identifies the parts most relevant to the query, and uses them to support the subsequent reasoning and generation process.
- Reasoning & Rich Media Report Generation: Leveraging relevant visual and textual cues retrieved from search, the model performs the necessary reasoning steps and generates a structured report, seamlessly integrating both visual and textual elements to match the task requirements.
We have optimized GLM-4.6V for frontend development, significantly shortening the “design to code” cycle.
- Pixel-Level Replication: By uploading a screenshot or design file, the model identifies layouts, components, and color schemes to generate high-fidelity HTML/CSS/JS code.
- Visual Debugging: Users can circle an area on a generated page screenshot and give natural language instructions (e.g., “Move this button left and make it dark blue”). The model automatically locates and corrects the corresponding code snippet.
GLM-4.6V aligns its visual encoder with a 128K context length, giving the model a massive memory capacity. In practice, this equates to processing ~150 pages of complex documents, 200 slide pages, or a one-hour video in a single inference pass.
- Financial Analysis: In testing, GLM-4.6V successfully processed financial reports from four different public companies simultaneously, extracting core metrics across documents and synthesizing a comparative analysis table without losing key details.
- Video Understanding: The model can perform global summarization on long videos while retaining the ability to perform fine-grained reasoning on temporal clues, such as summarizing goal events and timestamps in a full football match.
Overall Performance
We evaluated GLM-4.6V on over 20 mainstream multimodal benchmarks, including MMBench, MathVista, and OCRBench. The model achieves SOTA performance among open-source models of comparable scale in key capabilities such as multimodal interaction, logical reasoning, and long-context understanding.
Examples
- Intelligent Image-Text Content Creation & Layout
- Frontend Replication & Visual Interaction
- Multi-Image Processing Agent
- Full Object Detection and Recognition
Highlights Analysis
- Supports native multimodality, enabling direct processing of documents containing visual elements (e.g., images, tables, curves, etc.). This eliminates the need for cumbersome and error-prone preprocessing steps such as OCR and document parsing.
- In addition to text output, the model is capable of independent decision-making to locate the pages and regions where relevant content resides. It can also invoke tools via MCP for screenshot capture and embedding, generating well-illustrated reports.
- On the basis of in-depth paper reading and information analysis & consolidation, the model is endowed with reasoning capabilities, allowing it to express its own “insights” on specific topics.
Prompt
 Based on the key visualizations from the two papers, this research report delivers a comprehensive, illustration-integrated analysis of the bench described in the literature.
Based on the key visualizations from the two papers, this research report delivers a comprehensive, illustration-integrated analysis of the bench described in the literature.Display
ThinkCopy
Alright, here's the deal. The user wants me to act as a research report generator, analyzing two papers on AI-generated video benchmarks. I need to synthesize the information, focusing on the key visualizations and presenting it in a clear, integrated way. This is a common task, and I'm ready to dive in.
First, I need to understand the core of each paper. Paper 1, "AIGCBench," seems to be about evaluating Image-to-Video (I2V) generation. It's got a framework, datasets, and metrics. I'll need to dig into its structure, especially Figure 1, which shows the overall setup. Then, I'll look at the evaluation metrics, probably in Table 2. The visual comparisons of the generated videos in Figure 3 will be crucial for understanding the results. And, of course, the radar chart in Figure 4 will summarize the performance.
Next, Paper 2, "FETV," focuses on Text-to-Video (T2V) generation. It emphasizes fine-grained evaluation, categorizing prompts by content, attributes, and complexity. I'll need to understand the categorization framework, probably in Figure 1. The data distribution across these categories, shown in Figure 3 and 4, will be important. The radar charts in Figure 5 and 6 will show the model performance across different categories. And the leaderboards in Figure 7 will provide a quick overview of the rankings.
Now, the real work begins: synthesizing these two papers. I'll need to structure the report logically. I'll start with an introduction to set the stage. Then, I'll dive into the benchmarks themselves, highlighting their different focuses. I'll need to explain how AIGCBench is structured (Figure 1) and how FETV categorizes its prompts (Figure 1). Then, I'll compare the evaluation metrics, probably using Table 1 and Table 2. I'll need to discuss the visual results, using Figure 3 and Figures 5-7. Finally, I'll wrap it up with a conclusion, emphasizing the strengths and weaknesses of each benchmark.
I need to make sure I'm using the images effectively, referencing them correctly, and providing a clear, concise analysis. The user wants a "comprehensive, illustration-integrated analysis," so I need to deliver on that promise. Let's get started!
AnswerCopy
Of course. Here is a research report that provides a comprehensive, illustration-integrated analysis of the two benchmarks described in the literature.
Research Report: A Comparative Analysis of AIGCBench and FETV for Evaluating AI-Generated Video
This report analyzes two key research papers that introduce novel benchmarks for evaluating AI-generated video content. The first, AIGCBench, focuses on a comprehensive evaluation of Image-to-Video (I2V) generation, while the second, FETV, proposes a benchmark for the fine-grained evaluation of open-domain Text-to-Video (T2V) generation. By examining their methodologies, datasets, evaluation metrics, and results, we can understand the current state and challenges of automated video generation assessment.
1. AIGCBench: A Comprehensive Benchmark for Image-to-Video Generation
AIGCBench is designed to address the limitations of existing benchmarks by providing a unified and scalable framework for evaluating I2V models. Its primary goal is to offer a fair comparison of different algorithms under equivalent conditions.
Framework and Datasets:
The AIGCBench framework is divided into three core modules: datasets, video generation models, and evaluation metrics. As illustrated in Figure 1, the benchmark utilizes two types of datasets: real-world video-text pairs and a novel set of image-text pairs generated through a proprietary pipeline.
!<image_ref>[1, [[102, 75, 887, 296]], "Figure 1: Illustration of the AIGCBench framework."]</image_ref>
This pipeline, detailed in Figure 2, involves combining subjects, behaviors, backgrounds, and styles to create diverse prompts, which are then processed by GPT-4 for enhancement before being fed to a text-to-image model (Stable Diffusion) to generate the final image.
!<image_ref>[1, [[102, 71, 908, 466]], "Figure 2: Image-text dataset generation pipeline and results."]</image_ref>
Evaluation Metrics and Results:
AIGCBench evaluates I2V models across four critical dimensions:
Control-Video Alignment: How well the generated video matches the input image.
Motion Effects: The quality and plausibility of the motion.
Temporal Consistency: The coherence of the video across time.
Video Quality: The overall aesthetic and technical quality.
The benchmark evaluates five state-of-the-art models: VideoCrafter, I2VGen-XL, SVD, Pika, and Gen-2. The quantitative results, summarized in Table 2, show that Gen-2 performs best in video quality, while SVD and Pika show strong performance in control-video alignment and temporal consistency.
!<table_ref>[1, [[90, 75, 907, 235]], "Table 2: Quantitative analysis for different Image-to-Video algorithms."]</table_ref>
Qualitative comparisons in Figure 3 visually demonstrate the performance differences. For example, in the "knight running" prompt, Gen-2 produces a highly detailed and aesthetically pleasing video, whereas VideoCrafter and I2VGen-XL struggle to preserve the spatial structure of the original image.
!<image_ref>[1, [[92, 71, 910, 722]], "Figure 3: Qualitative comparison of five I2V algorithms on three different prompts."]</image_ref>
A user study with 42 participants was conducted to validate the metrics. The results, visualized in a radar chart in Figure 4, show that Pika excels in motion effects and temporal consistency, while Gen-2 is favored for video quality.
!<image_ref>[1, [[385, 75, 614, 266]], "Figure 4: Radar chart showing user preferences for different I2V algorithms."]</image_ref>
2. FETV: A Benchmark for Fine-Grained Text-to-Video Evaluation
FETV addresses the need for more nuanced evaluation of T2V models by introducing a multi-aspect categorization of prompts. Unlike benchmarks that provide only a single overall score, FETV breaks down evaluation into specific categories to reveal a model's strengths and weaknesses.
Multi-Aspect Categorization:
FETV's core innovation is its categorization of text prompts based on three orthogonal aspects, as shown in Figure 1:
Major Content: The primary subject (e.g., people, animals, scenery).
Attribute Control: Specific attributes the prompt aims to control (e.g., color, speed, motion direction).
Prompt Complexity: The complexity of the text prompt (simple, medium, complex).
This framework allows for a "fine-grained evaluation" that goes beyond a single score.
!<image_ref>[2, [[181, 71, 815, 314]], "Figure 1: Illustration of FETV's multi-aspect categorization."]</image_ref>
Evaluation and Results:
FETV evaluates four T2V models: CogVideo, Text2Video-zero, ModelScopeT2V, and ZeroScope. The evaluation is performed manually across four perspectives: static quality, temporal quality, overall alignment, and fine-grained alignment.
The results, presented in radar charts in Figure 5 and Figure 6, reveal significant variations in model performance across different categories. For instance, Figure 5 shows that ModelScopeT2V performs well on "static quality" for "people" and "scenery" but poorly on "artifacts" and "vehicles."
!<image_ref>[2, [[267, 71, 731, 472]], "Figure 5: Manual evaluation of static and temporal video quality across different major contents."]</image_ref>
Furthermore, Figure 6 demonstrates that models struggle with controlling specific attributes. For example, in the "fine-grained alignment" chart, all models show weakness in controlling "event order."
!<image_ref>[2, [[181, 525, 807, 722]], "Figure 6: Manual evaluation of video-text alignment across different attributes and complexities."]</image_ref>
The benchmark also includes leaderboards (Figure 7) that rank the models based on their overall performance in static quality, temporal quality, and alignment.
!<image_ref>[2, [[175, 71, 817, 196]], "Figure 7: Leaderboard on the FETV benchmark based on manual evaluation."]</image_ref>
3. Comparative Analysis and Conclusion
Both AIGCBench and FETV represent significant steps forward in the standardized evaluation of AI-generated video, but they target different tasks and evaluation philosophies.
Scope: AIGCBench focuses specifically on the I2V task, evaluating how well a model can animate a static image. FETV, in contrast, is designed for the more open-ended T2V task, where the model must generate a video from a text description.
Evaluation Granularity: FETV's primary strength is its "fine-grained" approach, using a detailed categorization system to pinpoint model weaknesses. AIGCBench provides a more holistic, four-dimensional score, offering a broader performance overview.
Methodology: AIGCBench combines both reference-dependent (video-dependent) and reference-free (video-free) metrics, along with human validation. FETV relies heavily on comprehensive manual evaluation to establish a ground truth, which it then uses to diagnose the reliability of automatic metrics.
In conclusion, these two benchmarks provide a more robust and multi-faceted way to assess AI video generation models. AIGCBench offers a comprehensive framework for fair I2V model comparison, while FETV pushes for a deeper, more nuanced understanding of T2V model capabilities. Together, they highlight the importance of diverse and detailed evaluation in driving progress in the field of AIGC.
Part 2. Image reference records
!<image_ref>[1, [[102, 75, 887, 296]], "Figure 1: Illustration of the AIGCBench framework."]</image_ref>
!<image_ref>[1, [[102, 71, 908, 466]], "Figure 2: Image-text dataset generation pipeline and results."]</image_ref>
!<image_ref>[1, [[92, 71, 910, 722]], "Figure 3: Qualitative comparison of five I2V algorithms on three different prompts."]</image_ref>
!<image_ref>[1, [[385, 75, 614, 266]], "Figure 4: Radar chart showing user preferences for different I2V algorithms."]</image_ref>
!<image_ref>[2, [[181, 71, 815, 314]], "Figure 1: Illustration of FETV's multi-aspect categorization."]</image_ref>
!<image_ref>[2, [[267, 71, 731, 472]], "Figure 5: Manual evaluation of static and temporal video quality across different major contents."]</image_ref>
!<image_ref>[2, [[181, 525, 807, 722]], "Figure 6: Manual evaluation of video-text alignment across different attributes and complexities."]</image_ref>
!<image_ref>[2, [[175, 71, 817, 196]], "Figure 7: Leaderboard on the FETV benchmark based on manual evaluation."]</image_ref>
Part 3. Table reference records
!<table_ref>[1, [[90, 75, 907, 235]], "Table 2: Quantitative analysis for different Image-to-Video algorithms."]</table_ref> Next, I need to call the image_reference tool to get the URL of the relevant image.
Rendered Result:
Highlights Analysis
- Enhanced code execution & visual consistency
- True support for continuous multi-round iterative web page generation capabilities
- Support for long web page generation and multi-round editing capabilities
Prompt
Help me generate the HTML code demonstrated in this video, which needs to include the clicks, redirects, interactions, and other features shown in the video.
Display
ThinkCopy
This is a complex task that requires me to recreate a dynamic webpage based on a series of video frames. The frames show the TripAdvisor website in Chinese. I need to build a React/Tailwind single-page application that mimics the interactions shown in the video.\n\nLet me analyze the key components and interactions from the video:\n\n1. Initial State: The homepage with a search bar, navigation menu, and a large hero image with a "Search" button.\n\n2. Navigation: The top navigation has options like "Discover" (发现), "Travel" (旅行), "Reviews" (点评), "More" (更多), a currency selector (USD), and a login button (登录).\n\n3. Search Bar: A prominent search bar with placeholder text for attractions, hotels, etc.\n\n4. Category Tabs: Below the search bar, there are tabs for different categories like "Search All" (搜索全部), "Hotels" (酒店), "Attractions" (景点玩乐), "Food" (美食).\n\n5. Scrolling Content: As the user scrolls down, different sections appear:\n - Hero banner with rotating images\n - "Find attractions that match your interests" section\n - Category cards for "Outdoor Activities" (户外活动), "Food" (美食), "Culture" (文化), "Water Activities" (水上活动)\n - "Explore Abu Dhabi" section\n - "Unmissable activities in exciting locations" section with activity cards\n - "Go far beyond: Discover more magical moments in Saudi" promotional section\n - "Inspiration to help you plan" section\n - "Big cities, happy holidays" section\n - "Unmissable iconic locations" section\n - "Travelers' Choice Awards" section\n - "Browse theme series" section\n\n6. Footer: The footer contains links to various pages and social media icons.\n\nNow I'll create the HTML/React code to replicate this interface. I'll focus on creating reusable components for repeating elements like activity cards and category cards.\n\nLet me start building the code:
Rendered Result:Highlights Analysis
- Stronger multi-image relational reasoning: Understands multiple screenshots from different sources and layouts, integrating information across images without requiring user-provided context per image.
- Precise multi-field extraction and validation: Automatically identifies key fields (order status, paid amount, merchant name, etc.) and filters entries based on business logic (e.g., excluding refunded orders).
- End-to-end cross-image logical reasoning: Performs the full reasoning chain—identify → validate → aggregate—to compute final results without manual step-by-step guidance.
- High robustness in real-world scenarios: Maintains consistent and reliable field recognition and logical judgment across diverse UI styles and layouts.
Prompt
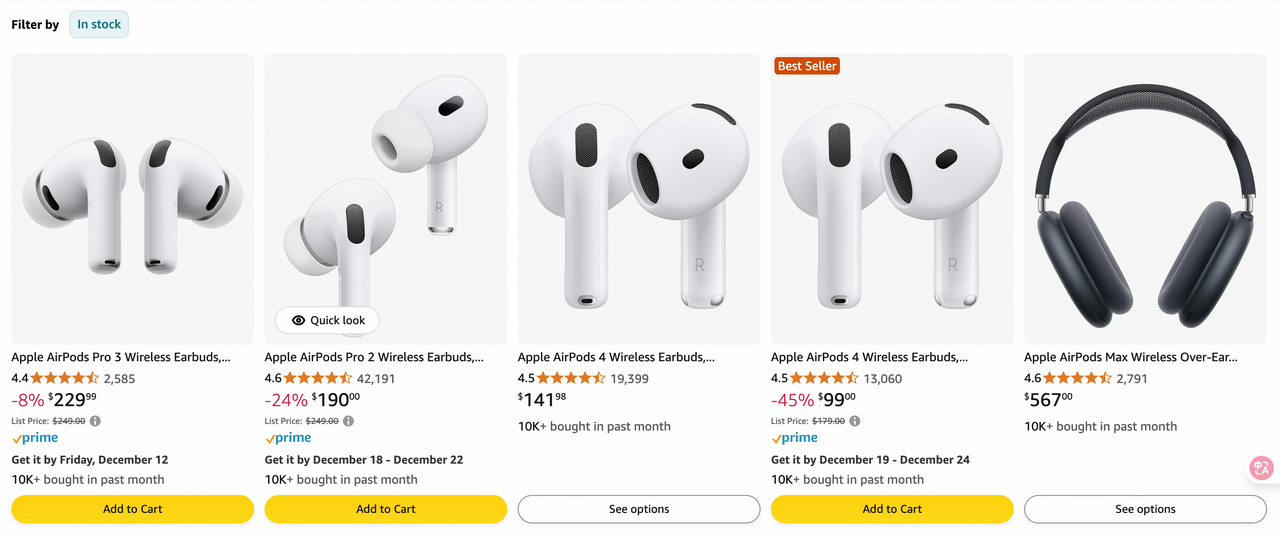
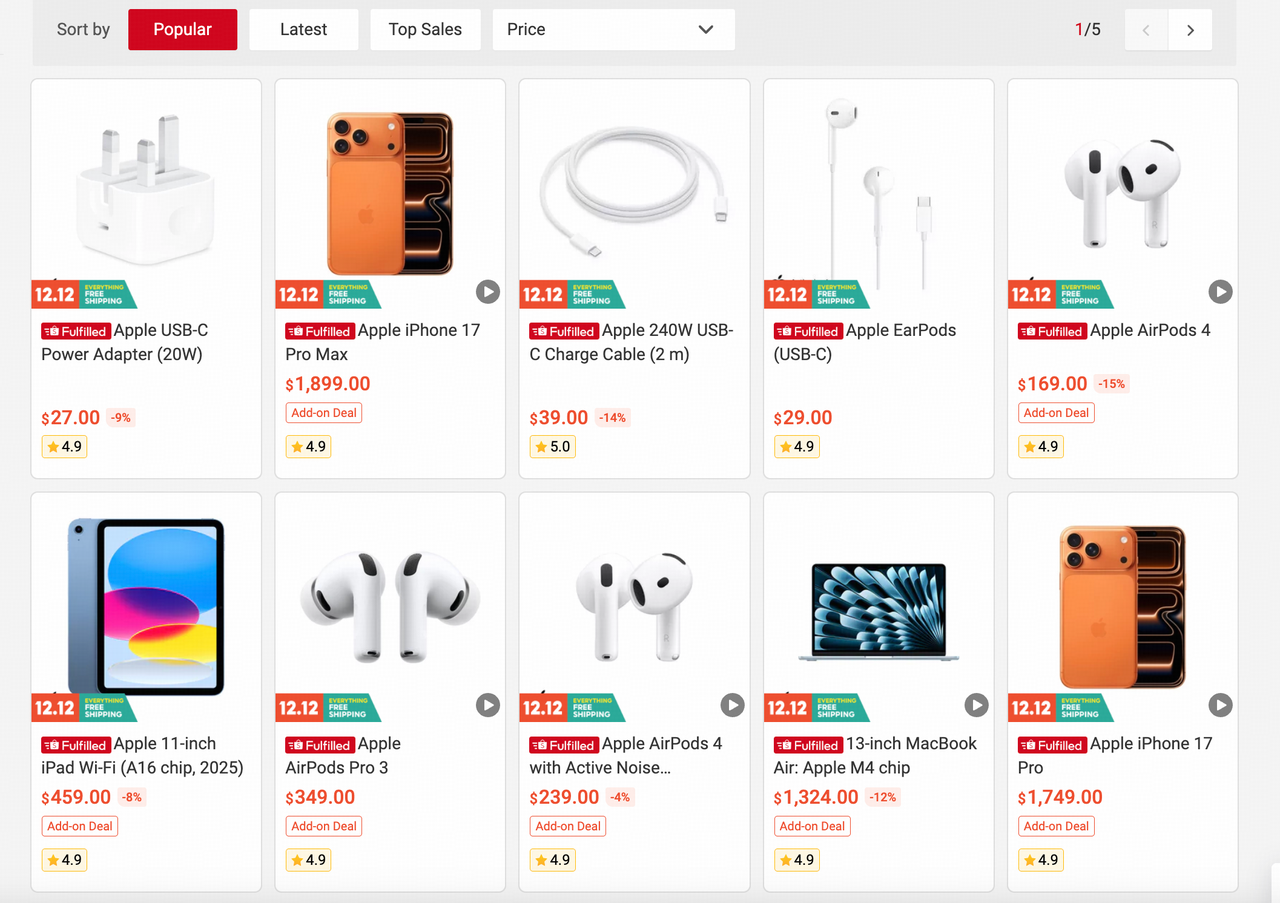
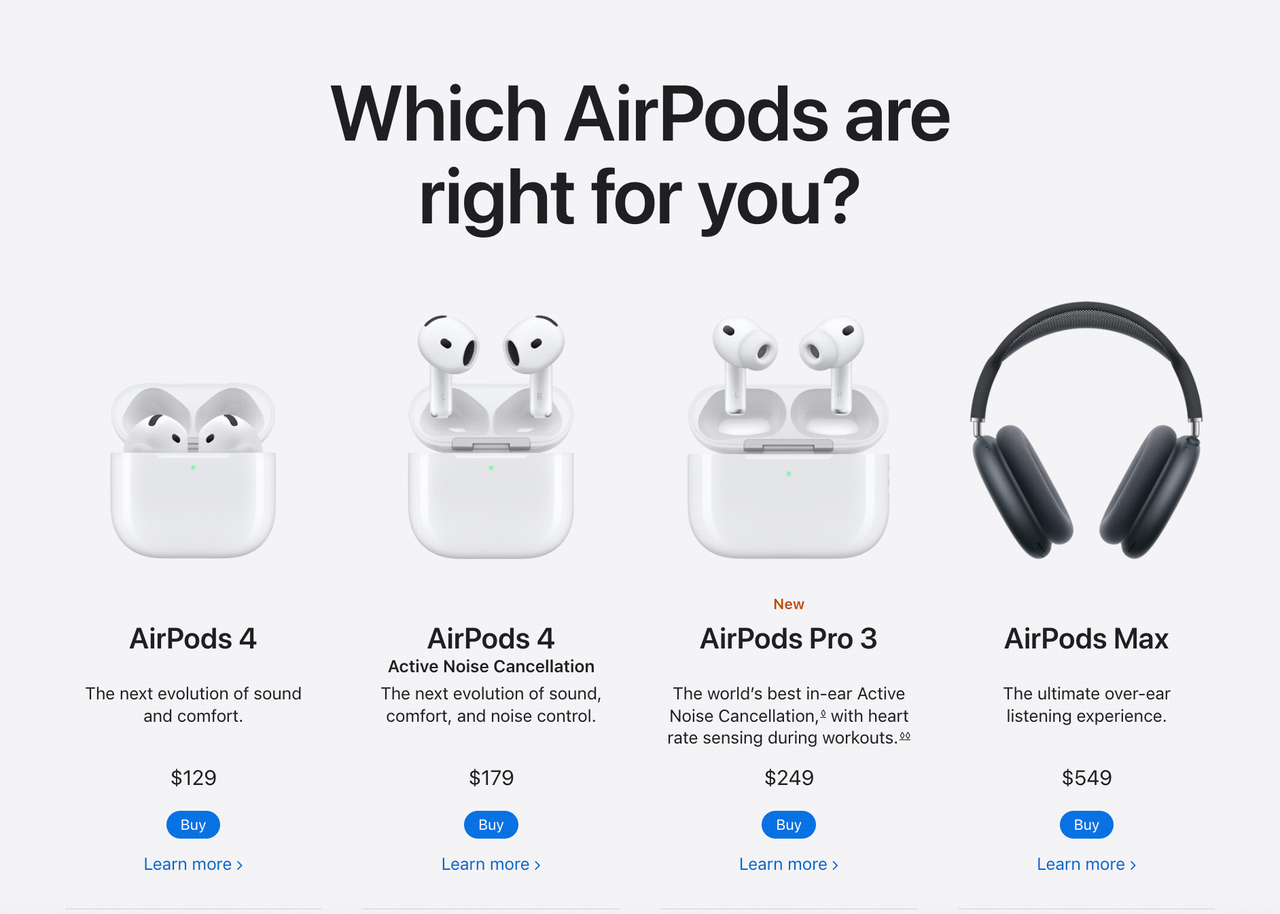 I want to buy AirPods 4. Could you circle the cheapest one for me?
I want to buy AirPods 4. Could you circle the cheapest one for me?Display
ThinkCopy
Okay, let's see. The user wants me to circle the cheapest AirPods 4. I've got three images to work with, and I need to find the best deal.
First, I'll look at the first image. It shows the standard AirPods 4 for $129 and the Active Noise Cancellation version for $179. The standard one is cheaper.
Next, I'll check the second image. Here, I see two AirPods 4 options: one at $141.98 and another at $99.00. The $99.00 one is clearly the cheapest so far.
Finally, the third image shows an AirPods 4 for $169.00.
Comparing all the prices, the $99.00 AirPods 4 from the second image is the cheapest. I need to circle that one. The bounding box for that product is at [599, 99, 799, 599]. I'll use that to draw the circle.
Rendered result: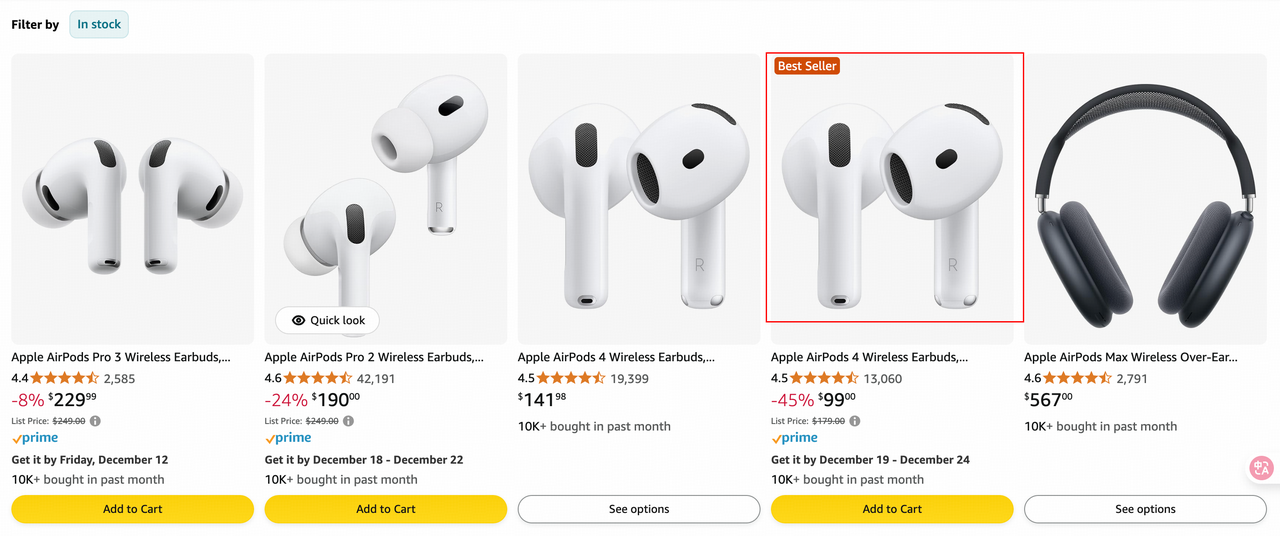
Highlights AnalysisFull Object Detection and Recognition: Based on the description of target categories or characteristics, output all qualified target detection boxes and their corresponding labels.
Prompt
 Identify the breeds of all cats in the image. Return the results in valid JSON format. The result should be a list, where each element in the list corresponds to a dictionary of target detection results. The dictionary keys are label and bbox_2d, with values being the detected cat breed and the result bounding box coordinates respectively.For example:
Identify the breeds of all cats in the image. Return the results in valid JSON format. The result should be a list, where each element in the list corresponds to a dictionary of target detection results. The dictionary keys are label and bbox_2d, with values being the detected cat breed and the result bounding box coordinates respectively.For example:[{"label": "Golden Shorthair-1", "bbox_2d": [1,2,3,4]},{"label": "Golden Shorthair-2", "bbox_2d": [4,5,6,7]}]Display
ThinkCopy
I now need to address the user’s question, and first, I have to recall the breeds of the cats in the image. Let’s start with the first cat on the left: it has stripes and a raised tail, so it should be a tabby cat (e.g., an American Shorthair or British Shorthair, but this type of striped pattern is typically tabby). The second cat is also striped with a slightly curved tail—could it also be a tabby? Wait, no. The third cat is light brown and white; could it be a Siamese cat? Because Siamese cats are usually pointed or bicolor with a light coat. The fourth cat is a small gray-and-white kitten—could it be a Ragdoll? Do Ragdolls have long fur? No, the kitten in the image appears to have short fur, so maybe an American Shorthair? Wait, let me think again: the fifth cat is striped with a very high, raised tail—could it be a Maine Coon? Because Maine Coons have long, fluffy tails, yes, the fifth cat has a large, bushy tail, so it should be a Maine Coon. The sixth cat is a small gray shorthair—probably a British Shorthair? The seventh cat is a long-haired gray cat with a fluffy tail—could it be a Norwegian Forest Cat? Because Norwegian Forest Cats have long fur and large tails. The eighth cat is a small striped kitten—likely an American Shorthair tabby.
Now let’s count the number of cats in the image: counting left to right, there are 8 cats total. Let me confirm each one:
First cat on the left: tabby pattern, short fur, upright tail—likely a "tabby cat".
Second cat: tabby pattern, curved tail, short fur—likely a "tabby cat" (same breed, different individual).
Third cat: light brown and white with pointed ears—likely a "Siamese cat" (Siamese cats are characterized by pointed coloration, pointed ears, and large eyes).
Fourth cat: gray-and-white, small build, short fur—likely an "American Shorthair" (American Shorthair: short fur, round face).
Fifth cat: striped with an especially long, fluffy tail—likely a "Maine Coon" (Maine Coons have long, dense fur on their tails).
Sixth cat: small gray shorthair—likely a "British Shorthair" (British Shorthair: round face, short fur).
Seventh cat: long-haired gray with a fluffy tail—likely a "Norwegian Forest Cat" (Norwegian Forest Cats have long fur, large tails, and a sturdy build).
Eighth cat (last on the right): small striped kitten, short fur—likely an "American Shorthair tabby".
Next, I need to verify if the breed names are accurate and if there are more precise labels. For example, the third cat: Siamese cats are marked by pointed coloration (e.g., an M-shaped marking on the head), pointed ears, and blue or green eyes. The third cat in the image has pointed ears and a light brown-and-white coat, which matches Siamese characteristics. The fifth cat’s tail is indeed long and dense, so it is a Maine Coon. The seventh cat fits the profile of a Norwegian Forest Cat with its long fur and large tail. The others are common tabby cats, and American/British Shorthairs are common shorthair breeds.
Then, I need to define the position of each cat using bbox_2d, which represents coordinates in the format [x1, y1, x2, y2] (where y1 = top, y2 = bottom, x1 = left, x2 = right). For example:
The first cat (far left): approximate bbox is [100, 150, 190, 820]
The second cat: [180, 330, 310, 850]
The third cat: [300, 350, 430, 900]
The fourth cat: [420, 520, 510, 920]
The fifth cat: [500, 260, 605, 850]
The sixth cat: [600, 450, 700, 870]
The seventh cat: [680, 120, 800, 830]
The eighth cat: [800, 480, 885, 830]
These coordinates are approximate (based on position in the image) and do not require precise pixel values—only general ranges.
Finally, organize this into a JSON list where each element is a dictionary. The label should be the breed plus a serial number (e.g., "Tabby Cat-1", "Tabby Cat-2", and so on).
AnswerCopy
[
{"label": "Tabby Cat-1", "bbox_2d": [95, 152, 192, 825]},
{"label": "Tabby Cat-2", "bbox_2d": [185, 332, 310, 852]},
{"label": "Siamese Cat-1", "bbox_2d": [295, 352, 428, 902]},
{"label": "American Shorthair-1", "bbox_2d": [415, 520, 508, 922]},
{"label": "Maine Coon-1", "bbox_2d": [498, 262, 603, 852]},
{"label": "British Shorthair-1", "bbox_2d": [603, 452, 697, 872]},
{"label": "Norwegian Forest Cat-1", "bbox_2d": [685, 120, 797, 832]},
{"label": "Tabby Cat-3", "bbox_2d": [802, 482, 882, 832]}
]
Quick Start
- cURL
- Python
- Java
Basic CallStreaming Call
Copy
curl -X POST \
https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer your-api-key" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-4.6v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://cloudcovert-1305175928.cos.ap-guangzhou.myqcloud.com/%E5%9B%BE%E7%89%87grounding.PNG"
}
},
{
"type": "text",
"text": "Where is the second bottle of beer from the right on the table? Provide coordinates in [[xmin,ymin,xmax,ymax]] format"
}
]
}
],
"thinking": {
"type":"enabled"
}
}'
Copy
curl -X POST \
https://api.z.ai/api/paas/v4/chat/completions \
-H "Authorization: Bearer your-api-key" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-4.6v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://cloudcovert-1305175928.cos.ap-guangzhou.myqcloud.com/%E5%9B%BE%E7%89%87grounding.PNG"
}
},
{
"type": "text",
"text": "Where is the second bottle of beer from the right on the table? Provide coordinates in [[xmin,ymin,xmax,ymax]] format"
}
]
}
],
"thinking": {
"type":"enabled"
},
"stream": true
}'
Install SDKVerify installationBasic CallStreaming Call
Copy
# Install the latest version
pip install zai-sdk
# Or specify a version
pip install zai-sdk==0.0.4
Copy
import zai
print(zai.__version__)
Copy
from zai import ZaiClient
client = ZaiClient(api_key="") # Enter your own APIKey
response = client.chat.completions.create(
model="glm-4.6v", # Enter the name of the model you want to call
messages=[
{
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://cloudcovert-1305175928.cos.ap-guangzhou.myqcloud.com/%E5%9B%BE%E7%89%87grounding.PNG"
}
},
{
"type": "text",
"text": "Where is the second bottle of beer from the right on the table? Provide coordinates in [[xmin,ymin,xmax,ymax]] format"
}
],
"role": "user"
}
],
thinking={
"type":"enabled"
}
)
print(response.choices[0].message)
Copy
from zai import ZaiClient
client = ZaiClient(api_key="") # Enter your own APIKey
response = client.chat.completions.create(
model="glm-4.6v", # Enter the name of the model you want to call
messages=[
{
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://cloudcovert-1305175928.cos.ap-guangzhou.myqcloud.com/%E5%9B%BE%E7%89%87grounding.PNG"
}
},
{
"type": "text",
"text": "Where is the second bottle of beer from the right on the table? Provide coordinates in [[xmin,ymin,xmax,ymax]] format"
}
],
"role": "user"
}
],
thinking={
"type":"enabled"
},
stream=True
)
for chunk in response:
if chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end='', flush=True)
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end='', flush=True)
Install SDKMavenGradle (Groovy)Basic CallStreaming Call
Copy
<dependency>
<groupId>ai.z.openapi</groupId>
<artifactId>zai-sdk</artifactId>
<version>0.3.0</version>
</dependency>
Copy
implementation 'ai.z.openapi:zai-sdk:0.3.0'
Copy
import ai.z.openapi.ZaiClient;
import ai.z.openapi.service.model.*;
import ai.z.openapi.core.Constants;
import java.util.Arrays;
public class GLM45VExample {
public static void main(String[] args) {
String apiKey = ""; // Enter your own APIKey
ZaiClient client = ZaiClient.builder().ofZAI()
.apiKey(apiKey)
.build();
ChatCompletionCreateParams request = ChatCompletionCreateParams.builder()
.model("glm-4.6v")
.messages(Arrays.asList(
ChatMessage.builder()
.role(ChatMessageRole.USER.value())
.content(Arrays.asList(
MessageContent.builder()
.type("text")
.text("Describe this image.")
.build(),
MessageContent.builder()
.type("image_url")
.imageUrl(ImageUrl.builder()
.url("https://aigc-files.bigmodel.cn/api/cogview/20250723213827da171a419b9b4906_0.png")
.build())
.build()))
.build()))
.build();
ChatCompletionResponse response = client.chat().createChatCompletion(request);
if (response.isSuccess()) {
Object reply = response.getData().getChoices().get(0).getMessage();
System.out.println(reply);
} else {
System.err.println("Error: " + response.getMsg());
}
}
}
Copy
import ai.z.openapi.ZaiClient;
import ai.z.openapi.service.model.*;
import ai.z.openapi.core.Constants;
import java.util.Arrays;
public class GLM45VStreamExample {
public static void main(String[] args) {
String apiKey = ""; // Enter your own APIKey
ZaiClient client = ZaiClient.builder().ofZAI()
.apiKey(apiKey)
.build();
ChatCompletionCreateParams request = ChatCompletionCreateParams.builder()
.model("glm-4.6v")
.messages(Arrays.asList(
ChatMessage.builder()
.role(ChatMessageRole.USER.value())
.content(Arrays.asList(
MessageContent.builder()
.type("text")
.text("Where is the second bottle of beer from the right on the table? Provide coordinates in [[xmin,ymin,xmax,ymax]] format")
.build(),
MessageContent.builder()
.type("image_url")
.imageUrl(ImageUrl.builder()
.url("https://cloudcovert-1305175928.cos.ap-guangzhou.myqcloud.com/%E5%9B%BE%E7%89%87grounding.PNG")
.build())
.build()))
.build()))
.stream(true)
.build();
ChatCompletionResponse response = client.chat().createChatCompletion(request);
if (response.isSuccess()) {
response.getFlowable().subscribe(
// Process streaming message data
data -> {
if (data.getChoices() != null && !data.getChoices().isEmpty()) {
Delta delta = data.getChoices().get(0).getDelta();
System.out.print(delta + "\n");
}},
// Process streaming response error
error -> System.err.println("\nStream error: " + error.getMessage()),
// Process streaming response completion event
() -> System.out.println("\nStreaming response completed")
);
} else {
System.err.println("Error: " + response.getMsg());
}
}
}