Overview
GLM-4.5V is Z.AI’s new generation of visual reasoning models based on the MOE architecture. With a total of 106B parameters and 12B activation parameters, it achieves SOTA performance among open-source VLMs of the same level in various benchmark tests, covering common tasks such as image, video, document understanding, and GUI tasks.Price
- Input: $0.6 per million tokens
- Output: $1.8 per million tokens
Input Modality
Video / Image / Text / File
Output Modality
Text
Maximum Output Tokens
16K
Usage
Web Page Coding
Web Page Coding
Analyze webpage screenshots or screen recording videos, understand layout and interaction logic, and generate complete and usable webpage code with one click.
Grounding
Grounding
Precisely identify and locate target objects, suitable for practical scenarios such as security checks, quality inspections, content reviews, and remote sensing monitoring.
GUI Agent
GUI Agent
Recognize and process screen images, support execution of commands like clicking and sliding, providing reliable support for intelligent agents to complete operational tasks.
Complex Long Document Interpretation
Complex Long Document Interpretation
Deeply analyze complex documents spanning dozens of pages, support summarization, translation, chart extraction, and can propose insights based on content.
Image Recognition and Reasoning
Image Recognition and Reasoning
Strong reasoning ability and rich world knowledge, capable of deducing background information of images without using search.
Video Understanding
Video Understanding
Able to parse long video content and accurately infer the time, characters, events, and logical relationships within the video.
Subject Problem Solving
Subject Problem Solving
Can solve complex text-image combined problems, suitable for K12 educational scenarios for problem-solving and explanation.
Resources
- API Documentation: Learn how to call the API.
Introducting GLM-4.5V
1
Open-Source Multimodal SOTA
GLM-4.5V, based on Z.AI’s flagship GLM-4.5-Air, continues the iterative upgrade of the GLM-4.1V-Thinking technology route, achieving comprehensive performance at the same level as open-source SOTA models in 42 public visual multimodal benchmarks, covering common tasks such as image, video, document understanding, and GUI tasks.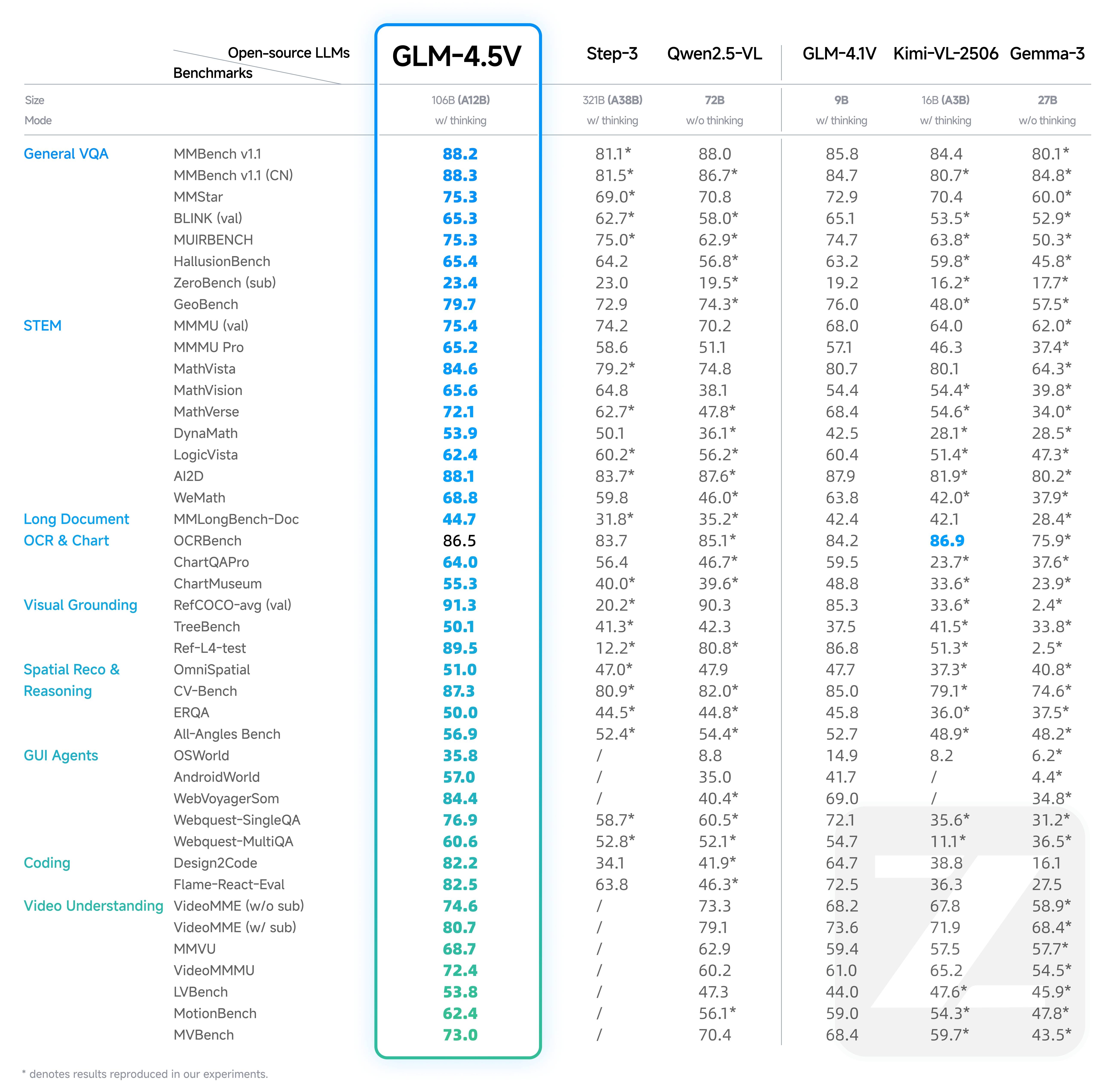
2
Support Thinking and Non-Thinking
GLM-4.5V introduces a new “Thinking Mode” switch, allowing users to freely switch between quick response and deep reasoning, flexibly balancing processing speed and output quality according to task requirements.
Examples
- Web Page Coding
- GUI Agent
- Chart Conversion
- Grounding
Prompt
 Please generate a high - quality UI interface using CSS and HTML based on the webpage I provided.
Please generate a high - quality UI interface using CSS and HTML based on the webpage I provided.Display
Screenshot of the rendered web page: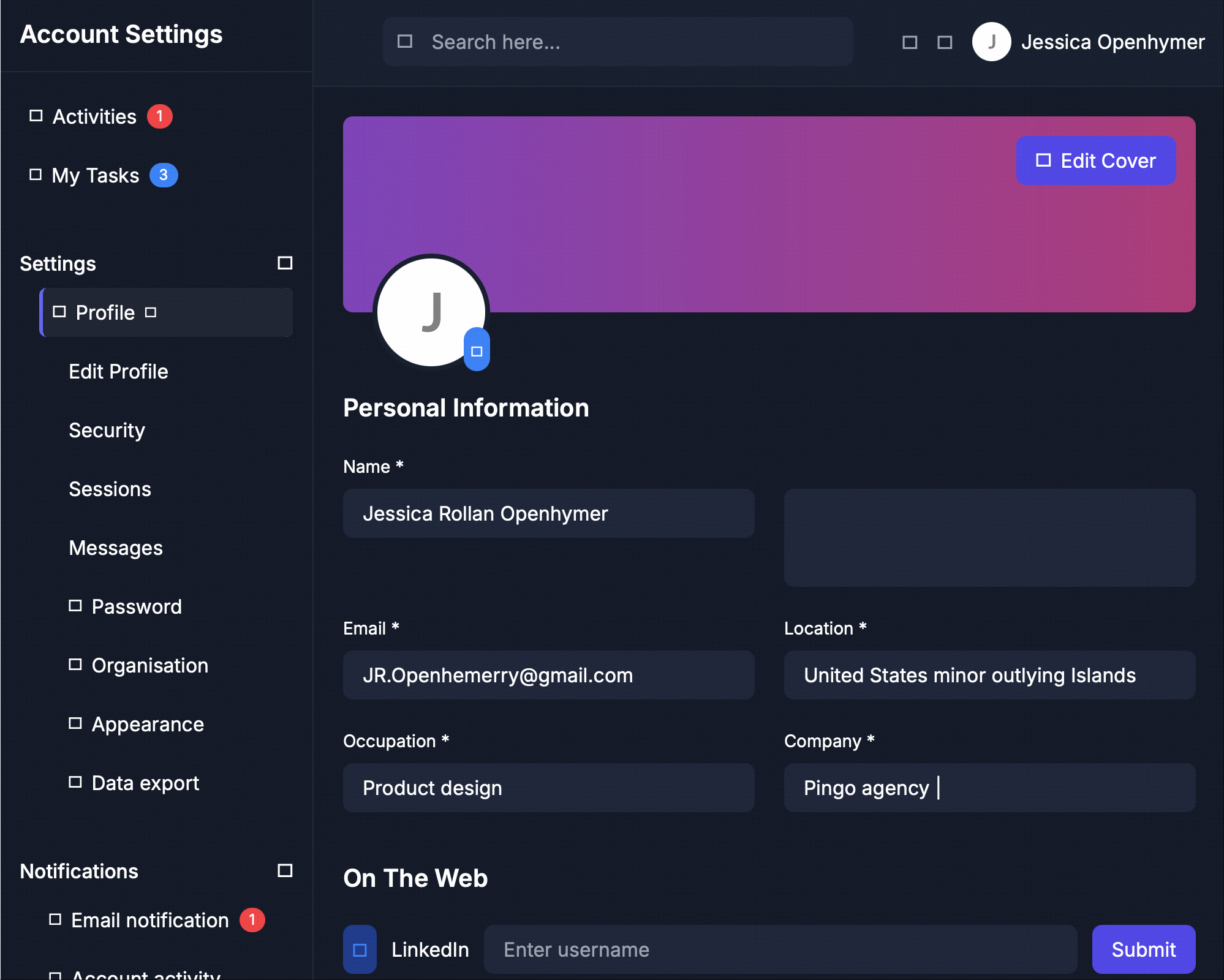
Quick Start
- cURL
- Python
- Java
Basic CallStreaming Call