Overview
GLM-4.5 and GLM-4.5-Air are our latest flagship models, purpose-built as foundational models for agent-oriented applications. Both leverage a Mixture-of-Experts (MoE) architecture. GLM-4.5 has a total parameter count of 355B with 32B active parameters per forward pass, while GLM-4.5-Air adopts a more streamlined design with 106B total parameters and 12B active parameters. Both models share a similar training pipeline: an initial pretraining phase on 15 trillion tokens of general-domain data, followed by targeted fine-tuning on datasets covering code, reasoning, and agent-specific tasks. The context length has been extended to 128k tokens, and reinforcement learning was applied to further enhance reasoning, coding, and agent performance. GLM-4.5 and GLM-4.5-Air are optimized for tool invocation, web browsing, software engineering, and front-end development. They can be integrated into code-centric agents such as Claude Code and Roo Code, and also support arbitrary agent applications through tool invocation APIs. Both models support hybrid reasoning modes, offering two execution modes: Thinking Mode for complex reasoning and tool usage, and Non-Thinking Mode for instant responses. These modes can be toggled via thethinking.typeparameter (with enabled and disabled settings), and dynamic thinking is enabled by default.
Input Modalities
Text
Output Modalitie
Text
Context Length
128K
Maximum Output Tokens
96K
GLM-4.5 Serials
GLM
GLM-4.5
Our most powerful reasoning model, with 355 billion parameters
AIR
GLM-4.5-Air
Cost-Effective Lightweight Strong Performance
X
GLM-4.5-X
High Performance Strong Reasoning Ultra-Fast Response
AirX
GLM-4.5-AirX
Lightweight Strong Performance Ultra-Fast Response
FLASH
GLM-4.5-Flash
Free Strong Performance Excellent for Reasoning Coding & Agents
Capability
Deep Thinking
Enable deep thinking mode for more advanced reasoning and analysis
Streaming Output
Support real-time streaming responses to enhance user interaction experience
Function Call
Powerful tool invocation capabilities, enabling integration with various external toolsets
Context Caching
Intelligent caching mechanism to optimize performance in long conversations
Structured Output
Support for structured output formats like JSON, facilitating system integration
Introducting GLM-4.5
Overview
The first-principle measure of AGI lies in integrating more general intelligence capabilities without compromising existing functions. GLM-4.5 represents our first complete realization of this concept. It combines advanced reasoning, coding, and agent capabilities within a single model, achieving a significant technological breakthrough by natively fusing reasoning, coding, and agent abilities to meet the complex demands of agent-based applications. To comprehensively evaluate the model’s general intelligence, we selected 12 of the most representative benchmark suites, including MMLU Pro, AIME24, MATH 500, SciCode, GPQA, HLE, LiveCodeBench, SWE-Bench, Terminal-bench, TAU-Bench, BFCL v3, and BrowseComp. Based on the aggregated average scores, GLM-4.5 ranks second globally among all models, first among domestic models, and first among open-source models.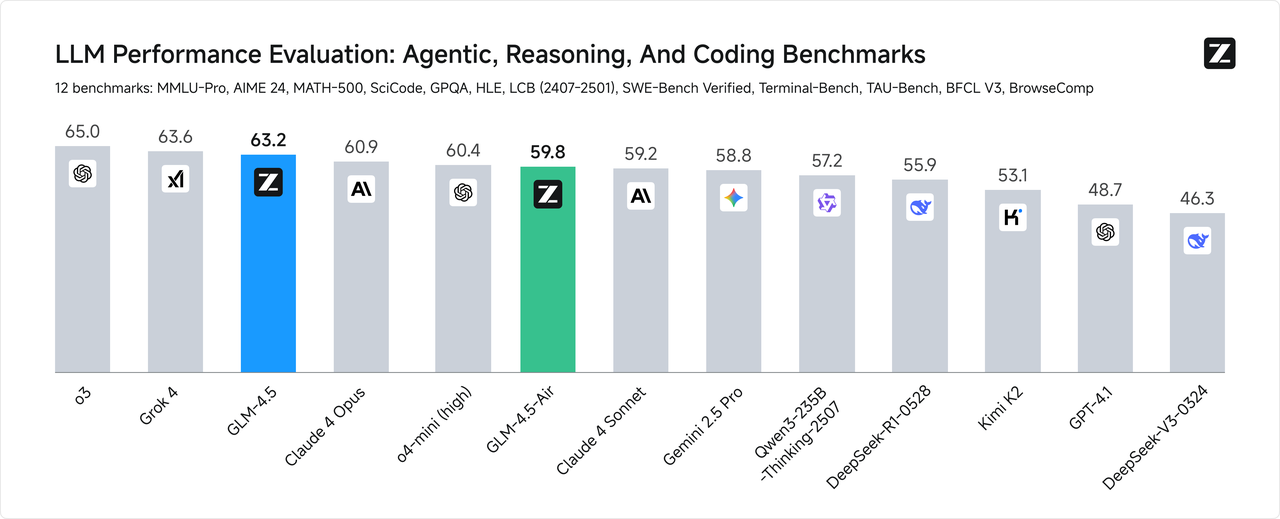
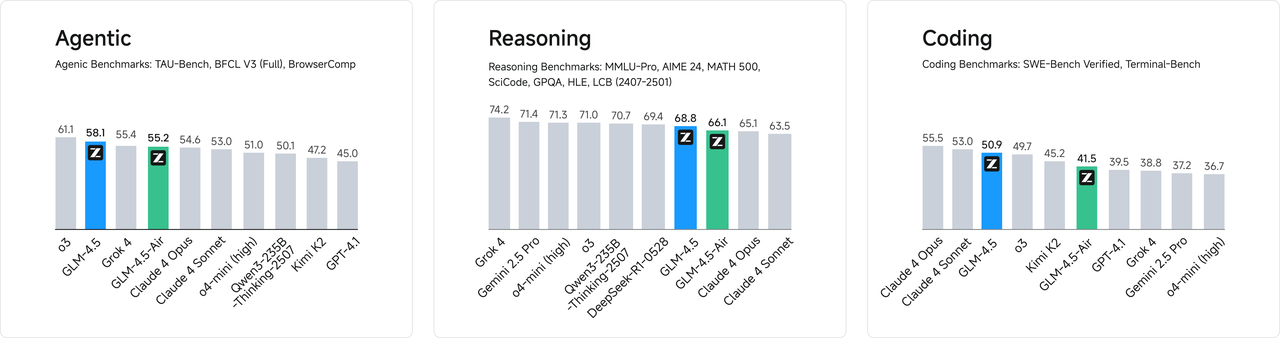
Higher Parameter Efficiency
GLM-4.5 has half the number of parameters of DeepSeek-R1 and one-third that of Kimi-K2, yet it outperforms them on multiple standard benchmark tests. This is attributed to the higher parameter efficiency of GLM architecture. Notably, GLM-4.5-Air, with 106 billion total parameters and 12 billion active parameters, achieves a significant breakthrough—surpassing models such as Gemini 2.5 Flash, Qwen3-235B, and Claude 4 Opus on reasoning benchmarks like Artificial Analysis, ranking among the top three domestic models in performance. On charts such as SWE-Bench Verified, the GLM-4.5 series lies on the Pareto frontier for performance-to-parameter ratio, demonstrating that at the same scale, the GLM-4.5 series delivers optimal performance.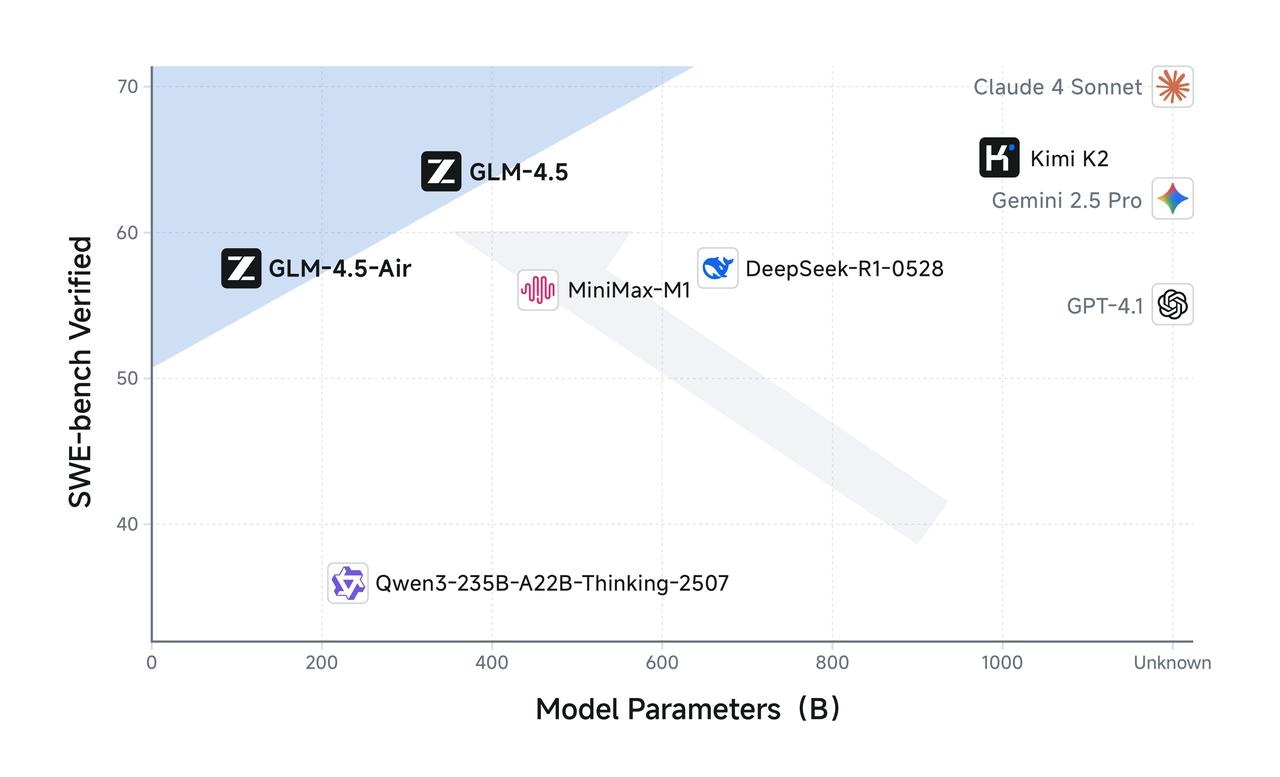
Low Cost, High Speed
Beyond performance optimization, the GLM-4.5 series also achieves breakthroughs in cost and efficiency, resulting in pricing far lower than mainstream models: API call costs are as low as $0.2 per million input tokens and $1.1 per million output tokens. At the same time, the high-speed version demonstrates a generation speed exceeding 100 tokens per second in real-world tests, supporting low-latency and high-concurrency deployment scenarios—balancing cost-effectiveness with user interaction experience.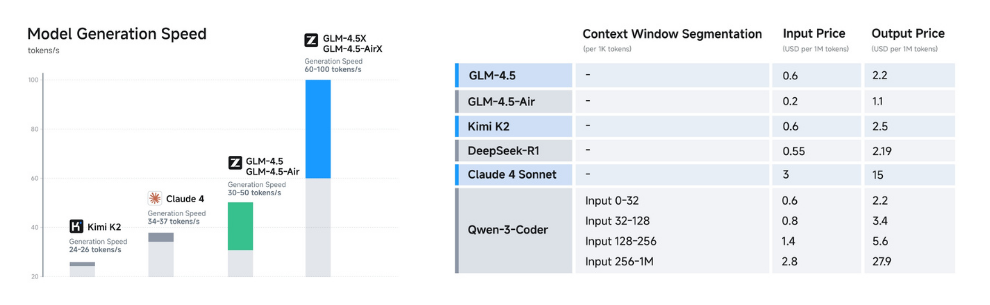
Real-World Evaluation
Real-world performance matters more than leaderboard rankings. To evaluate GLM-4.5’s effectiveness in practical Agent Coding scenarios, we integrated it into Claude Code and benchmarked it against Claude 4 Sonnet, Kimi-K2, and Qwen3-Coder. The evaluation consisted of 52 programming and development tasks spanning six major domains, executed in isolated container environments with multi-turn interaction tests. As shown in the results (below), GLM-4.5 demonstrates a strong competitive advantage over other open-source models, particularly in tool invocation reliability and task completion rate. While there remains room for improvement compared to Claude 4 Sonnet, GLM-4.5 delivers a largely comparable experience in most scenarios. To ensure transparency, we have released all 52 test problems along with full agent trajectories for industry validation and reproducibility.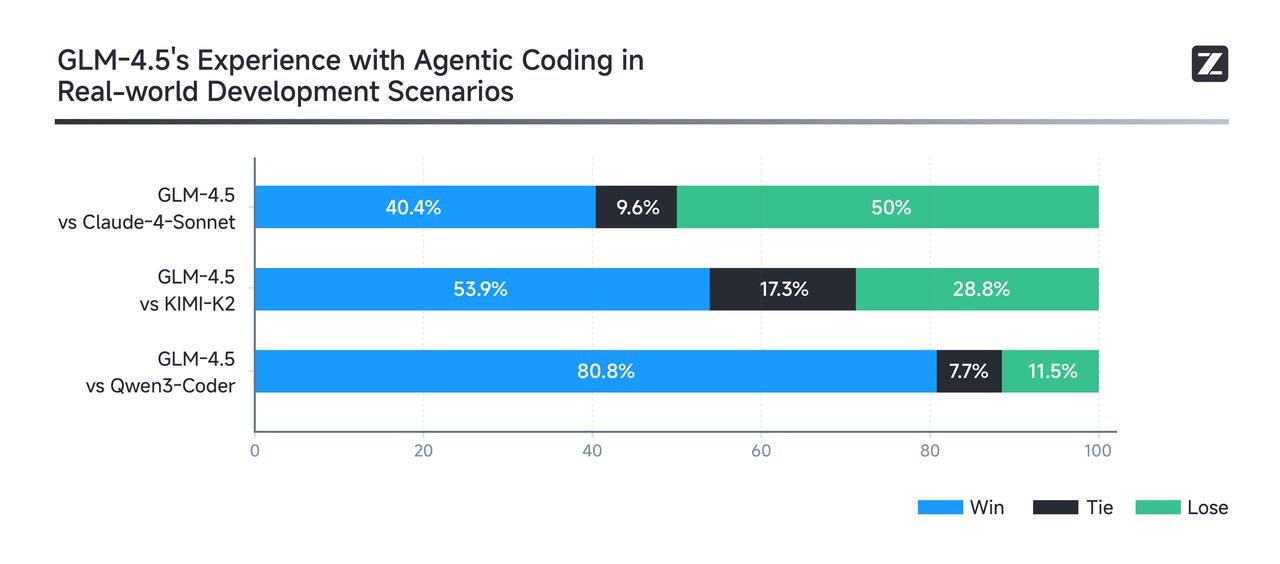
Usage
- Web Development
- AI Assistant
- Smart Office
- Intelligent Question Answering
- Complex Text Translation
- Content Creation
- Virtual Characters
Core Capability: Coding Skills → Intelligent code generation | Real-time code completion | Automated bug fixing
- Supports major languages including Python, JavaScript, and Java.
- Generates well-structured, scalable, high-quality code based on natural language instructions.
- Focuses on real-world development needs, avoiding templated or generic outputs.
Resources
- API Documentation: Learn how to call the API.
Quick Start
Thinking Mode
GLM-4.5 offers a “Deep Thinking Mode” that users can enable or disable by setting thethinking.type parameter. This parameter supports two values: enabled (enabled) and disabled (disabled). By default, dynamic thinking is enabled.
- Simple Tasks (No Thinking Required): For straightforward requests that do not require complex reasoning (e.g., fact retrieval or classification), thinking is unnecessary. Examples include:
- When was Z.AI founded?
- Translate the sentence “I love you” into Chinese.
- Moderate Tasks (Default/Some Thinking Required): Many common requests require stepwise processing or deeper understanding. The GLM-4.5 series can flexibly apply thinking capabilities to handle tasks such as:
- Why does Jupiter have more moons than Saturn, despite Saturn being larger?
- Compare the advantages and disadvantages of flying versus taking the high-speed train from Beijing to Shanghai.
- Explain in detail how different experts in a Mixture-of-Experts (MoE) model collaborate.
- Based on the recent week’s fluctuations of the Shanghai Composite Index and current political information, should I invest in a stock index ETF? Why?
Samples Code
- cURL
- Official Python SDK
- Official Java SDK
- OpenAI Python SDK
Basic CallStreaming Call